First of all, let me say that ValueTask was introduced in .NET Core 2.0 for a very specific scenario, when a method can return a result either synchronously or asynchronously. For example, let’s imagine a method with a few execution paths: using an "if" or a "switch" statement (it really doesn’t matter). At least one execution path must return the result synchronously (for example, a cached value or a constant returned due to business logic or validation failure). And, of course, there should also be an execution path that returns the result asynchronously (for example, from a network call or a service, etc.). For example:
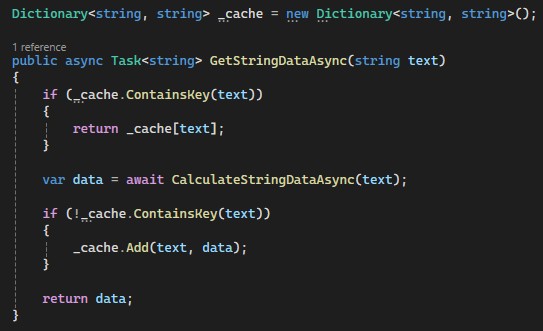
Example of the method
In most cases, the cache exists, and because of this, the synchronous part of the code is executed. But if there is no cache, we will call the asynchronous method in our code, retrieve the data, and store it in the cache. So this is the method that can be either synchronous or asynchronous, and this is where ValueTask comes into play. But how exactly can it help us here? The point is that this method always returns a Task, regardless of which execution path is taken. But Task is a reference type; it is allocated on the heap. And if we return it from inside an "if" statement, do we really need to create a Task, allocate memory for it, and so on? No, it is unnecessary and even redundant. So, you can change the return type of the method to ValueTask, like this:
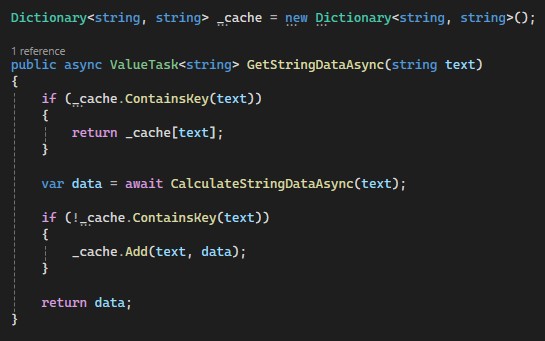
The same method with the ValueTask return type
What is the difference? ValueTask is a struct; therefore, it is a value type. It can represent either a Task or a T (your type), but not both, of course. So only if the execution path hits the asynchronous branch it will create a Task; otherwise, a regular T (an integer in our case) will be returned. If you call the method thousands or millions of times, the difference may be crucial.
At the same time, there is also an optimization in .NET for Task<int> objects. When a Task returns an int in the range from -1 to 8, it actually returns the same cached object. Hovewer, ValueTask is still much more efficient, because this optimization is merely an implementation detail of .NET and may change in the future. In addition, this optimization covers only a limited set of scenarios.
Let`s take a look at a particular example. The CalculateStringDataAsync method simulates some asynchronous logic and returns a hash of the string:
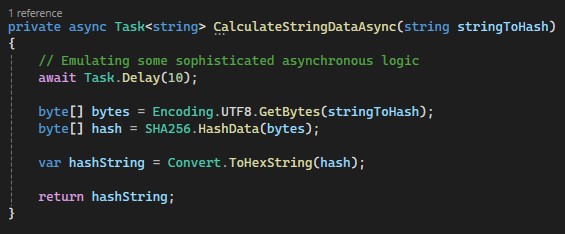
The CalculateStringDataAsync method
I also created two classes, StringHandlerTask and StringHandlerValueTask, each with a GetStringDataAsync method (shown above). The only difference between them is that in the first class the method returns a Task, and in the second one it returns a ValueTask. I also created the RunBenchmark method that calls both these methods and measures their execution time:
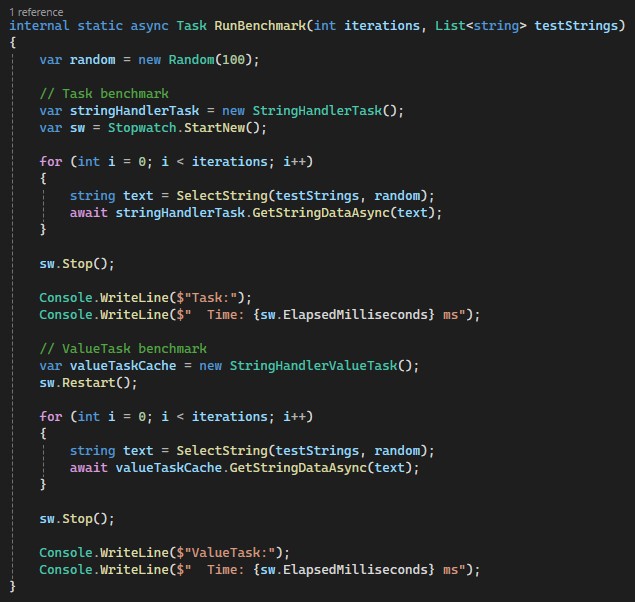
The RunBenchmark method
This method takes the number of iterations and a list of strings as parameters. The first part of the method creates an instance of the StringHandlerTask class and initializes a timer. After that, in a loop, we select a string (via the method shown below) from the list of test strings and execute the asynchronous test logic on it. At this stage asynchronous logic is implemented using Task. Next, we stop the timer and display the measurement results. The second part of the method is similar; the only difference is that the asynchronous logic is implemented using ValueTask. And here is the implementation of the SelectString method - there is nothing special:
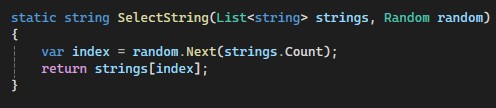
The SelectString method
According to this logic, the chance of hitting the cache increases with each new iteration. And here are the benchmark results for 500 iterations with a string list length of 50:
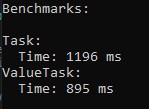
Benchmark results
As you can see, in our example, ValueTask performs more than 25% better than the Task implementation. Of course, I ran it many times, and the measurement results are approximately the same each time. So thank you for reading - I hope you found it worthwhile.